


Chegou a hora de aprender banco de dados (Parte 1)
Vá além de SQL e aprenda banco de dados com profundidade

Banco de dados sempre foi um assunto que me interessou pouco. Sei lá, SQL não me encanta. Mas ultimamente tenho estudado cada vez mais sobre arquitetura e design de sistemas, e apesar de sempre ter reconhecido o valor da camada de armazenamento, comecei a admirar mais a área.
Como Bancos de Dados funcionam?
No começo desse ano, no TLDR DevOps, fui apresentado ao artigo “Databases in 2024: A Year in Review - Andy Pavlo”.
Com um senso de humor duvidoso e um conteúdo de alta qualidade, acabei seguindo alguns links e caindo num vídeo sensacional:
O cara simplesmente ilustra e explica como desde os anos 1980, desenvolvedores vêm tentando substituir o Relational Model - e falhando miseravelmente.
Hoje em dia, com o PostgreSQL e suas várias extensões e wrappers, fica evidente que o modelo relacional de fato faz força para voltar a tona e se mostrar como a solução mais viável e escalável para a maioria das aplicações.
Então COMÉQUI eu e você vamos nos intitular profissionais de DevOps, desenvolvedores, arquitetos, ou o que quer que seja, sem saber esse trem direito? Tem que ter muita cara de pau.
Continuei seguindo alguns links e pesquisando sobre o Andy Pavlo para chegar a feliz conclusão que os seus cursos de banco de dados estão disponíveis GRATUITAMENTE no YouTube. Infelizmente acabaram as minhas desculpas para não aprender.
O curso é muito novo, do final de 2024, e conta com participação de empresas relevantes e bancos atuais como Databricks, Redshift, TiDB, e mais.
E isso é o curso BÁSICO. Ainda tem o curso avançado.
Highlights do curso
O curso tem 26 aulas de aproximadamente 1:30h. São muitas horas e nem todo mundo quer ou tem tempo para assistir uma aula convencional de faculdade. No momento que lhes escrevo esse post, eu assisti as 5 primeiras aulas, e sinceramente: vale a pena.
Mas se você já é familiarizado com os conceitos ou só quer algumas referências rápidas, não vou te deixar na mão também!
⚡ Os vídeos e links estão com o timestamp, então você não vai nem ter que procurar onde a parte interessante começa!
Técnicas avançadas de SQL
Para ir além de `SELECT` e `WHERE` e aprender sobre:
Aggregation + Group By
String / Date / Time Operations
Output Control + Redirection
Window Functions
Nested Queries
Lateral Joins
Common Table Expressions
Armazenamento em Bancos de Dados
Quer entender de verdade qual a relevância do page size por exemplo? Quais algoritmos e estruturas são utilizadas para armazenar os dados? Chegou a hora.
Visão macro de como um DBMS funciona, da interpretação da query até o armazenamento
Slotted Pages (PostgreSQL, MSSQL, DuckDB, SQLite), Log-Structured Storage (LSM Trees) (Cassandra, CockroachDB, RocksDB, LevelDB, Apache HBASE, etc.) e Index Organized (SQLite, MySQL, Oracle, MSSQL)
Quais são os diferentes tipos de workloads: (OLTP, OLAP, Hybrid) e como eles influenciam na tomada de decisão sobre como as tuples devem ser armazenadas
N-Ary Storage Model (NSM) - row store, ideal para workloads OLTP
Decomposition Storage Model (DSM) - column store, ideal para workloads OLAP
Partition Attributes Across (PAX) - hybrid, combinação do processamento rápido do column store, mantendo a localidade espacial do row store. Formatos famosos como o Parquet, ORC e Arrow.
⏰ Uma pequena pausa aqui para comentários e ilustrações sobre porque row store é útil para workloads OLTP (On-line Transaction Processing) e column store é útil para workloads OLAP (On-line Analytical Processing)
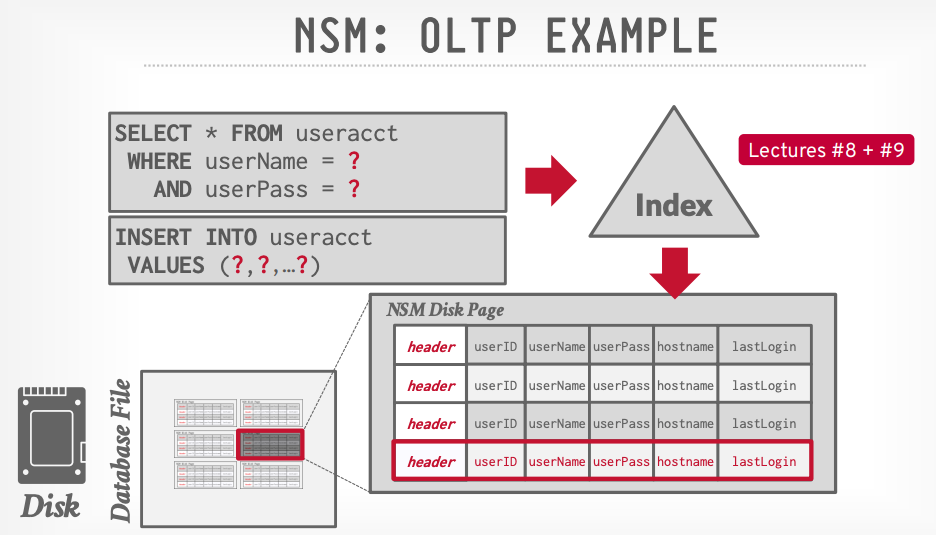
Um sistema NSM (row) armazena as tuplas continuamente em uma página:

O que significa que uma query transacional vai acessar os dados de forma contínua também:
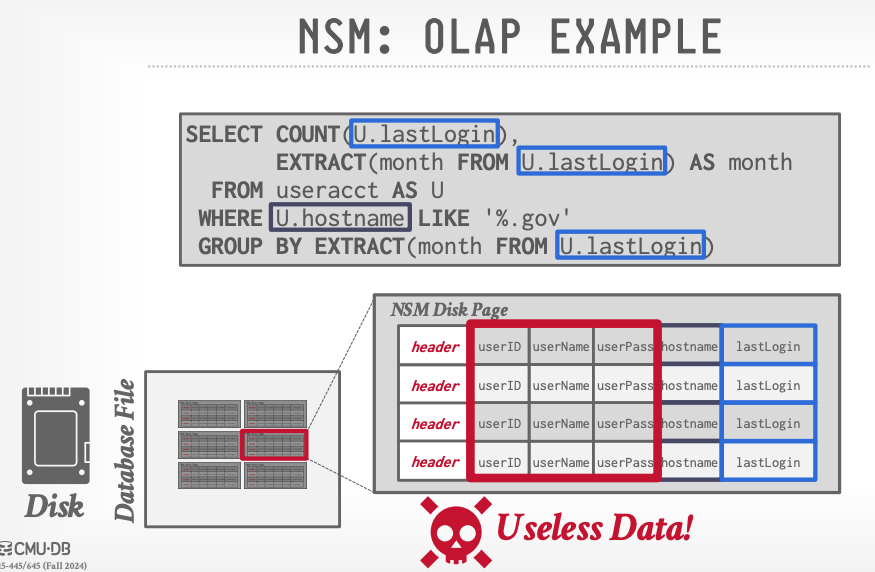
Já uma query OLAP tende a forçar múltiplas varreduras da página inteira para realizar filtros e agregar valores, além de alocar memória e gerar operações de IO com dados que não são necessários para as operações:
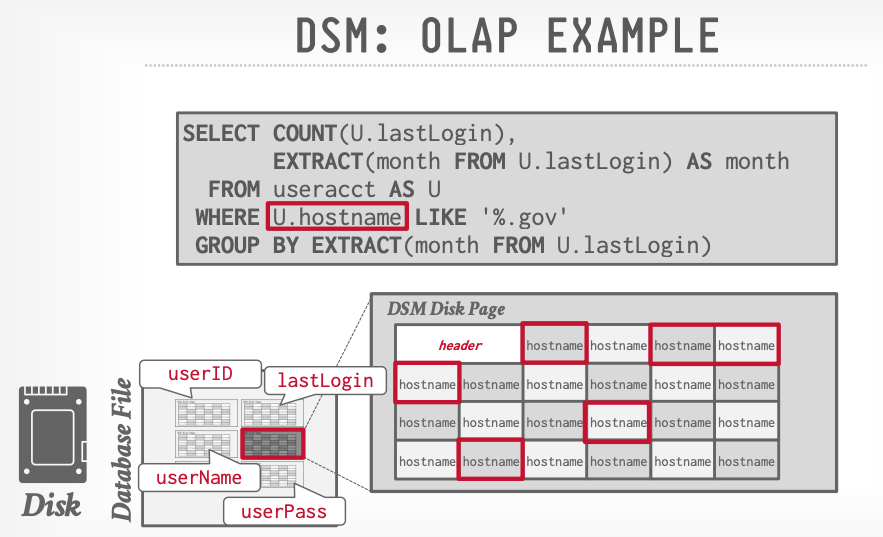
Em um sistema DSM (column), cada atributo é armazenado de forma sequencial em n páginas, permitindo uma varredura contínua no caso de queries que exigem filtros e análises dessa natureza:
Estou tentando assistir uma aula por dia, então vou finalizar essa primeira parte por aqui para garantir um fluxo de conteúdo contínuo, e pra ver se eu capturo seu interesse para aprender junto comigo!
Só esses primeiros vídeos já abriram meus olhos sobre o funcionamento básico das engines, além de servirem como uma excelente introdução a tópicos extremamente relevantes como o armazenamento colunar.
Eu trabalho há anos com a AWS, e agora entendo um pouco melhor como e porque a combinação S3 + Parquet + Glue funciona tão bem. É muito cômodo simplesmente aceitar algumas coisas, e eu já percebi que esse curso será uma excelente maneira de sair da minha zona de conforto.
Na Parte 2 falaremos das aulas #6 a #12, cobrindo conceitos como:
Gerenciamento de memória
Estruturas de dados como B+ Trees e indexes
Algoritmos de agregação, joins e rank
A minha expectativa é que essas aulas sejam uma excelente introdução prática a algoritmos e estruturas de dados comumente vistos em plataformas como o LeetCode e em entrevistas, o que é ótimo. Se o tempo permitir, quem sabe não tento implementar os algoritmos em alguma linguagem de programação diferente?
Até a próxima!